Evolving a Wiki Markup Parser
Initially my Textile-J open-source project started out with modest goals: to provide a Textile markup parser for Java. Since the project has started, interest in other features drove evolution of the code-base in some interesting directions. This article discusses architectural choices and the evolution of the Textile-J parser architecture to meet changing requirements.
The initial design of the Textile-J parser was a monolithic stateful parser class that used regular expressions and local variables to parse the markup. The results of parsing markup were passed to the XMLStreamWriter interface as HTML elements and attributes. This architecture worked fine initially, as it allowed me to evolve my understanding of Textile markup structure (blocks, phrases and tokens) and the XMLStreamWriter provided a solid means of outputting XHTML.
Feature: Multiple Output Formats
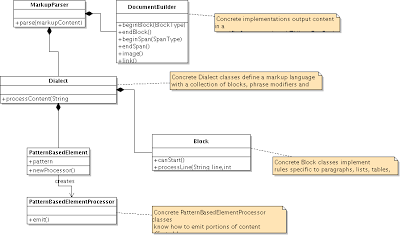
The first major feature request was to support multiple output formats: HTML and DocBook. This required a major rethink of the parser. While XMLStreamWriter was a great means of outputting XML, the parser had to know that HTML was the output format. After some thinking and reviewing the ever-relevant GOF Design Patterns book, I recognized that the Builder design pattern was an ideal fit. So I created a new interface called DocumentBuilder, with an HtmlDocumentBuilder and DocbookDocumentBuilder implementations. Now the parser need not know about the output format, meaning that a single parser could drive multiple output formats.
Feature: Markup Dialects
Next extensions to the Textile markup language were requested. For example, Confluence markup dialect is very similar to Textile but has some additional syntax features. With a better understanding of markup structure (blocks, phrases and tokens) I designed a new 'Dialect' concept that allowed for markup extensions to be added to the base Textile language. The 'Dialect' design was object-oriented, making extensions modular and relatively easy to add without disturbing the base markup parser code.
Feature: Markup Languages
While the approach of markup dialects worked well for adding extensions to Textile parsing, it did not solve the problem of fully supporting new markup languages. Dialects at this point were only capable of extending Textile.
Community demand for supporting new markup languages was increasing, including requests for MediaWiki and Markdown. Supporting these languages was not possible using the existing Textile parser, as the markup rules of Textile were embedded in a single monolithic class. After some prolonged hesitation (this would be a big job), I got down to the design of a complete rewrite of the parser architecture.
The first step was to read up on various markup languages. Most languages that I've looked at use a simple line-based parsing approach that consists of dividing the markup into blocks, phrases and tokens. Blocks are usually multi-line constructs that have certain attributes, such as paragraphs and lists. Phrases are modifiers that affect text on a single line, and tokens are match-and-replace elements in the text.
Requirements of the new design had to include:
- ease of adding new markup languages
- modular object-oriented design for better maintainability
- facilitate comprehensive JUnit tests
- easier learning curve for community contributions
- pluggable architecture
- output format agnostic
Using my experience with the previous Dialect design here's what I came up with:

The parser delegates all language-specific parsing to the Dialect. The Dialect defines a language with a collection of Blocks, phrase modifiers (PatternBasedElement) and tokens (PatternBasedElement). Blocks implement rules specific to paragraphs, lists, tables, etc. Concrete PatternBasedElementProcessor classes know how to emit portions of content affected by markup (phrase modifiers or tokens).
So far the following languages have been imlemented using this new architecture:
- Textile
- MediaWiki (a la WikiPedia fame)
- Confluence
I hope to see contributions from the community for supporting other languages, such as Markdown and Creole.
Recent Posts
- Flutter Maps With Vector Tiles
- Raspberry Pi SSH Setup
- Raspberry Pi Development Flow
- Troubleshooting Android App Crash on Chromebook
- Article Index
subscribe via RSS